


Reviewed this week:
⭐Training Language Models to Self-Correct via Reinforcement Learning
Scaling Smart: Accelerating Large Language Model Pre-training with Small Model Initialization
Promptriever: Instruction-Trained Retrievers Can Be Prompted Like Language Models
⭐: Papers that I particularly recommend reading.
New code repositories:
I maintain a curated list of AI code repositories here:
⭐Training Language Models to Self-Correct via Reinforcement Learning
LLMs have shown good performances in reasoning tasks such as mathematical problem-solving and coding. Despite their capabilities, they often struggle to implement algorithms that allow them to improve their responses through computation and interaction. Previous approaches to instill self-correction either depend on prompt engineering or require fine-tuning with additional models, but these methods have limitations and often fail to produce meaningful self-corrections.
The authors introduce Self-Correction via Reinforcement Learning (SCoRe), a new approach that enables LLMs to correct their own mistakes "on-the-fly" without any oracle or external feedback. SCoRe trains a single model using self-generated data through online multi-turn reinforcement learning. This method addresses challenges found in supervised fine-tuning, such as the model's tendency to make minimal edits without substantial improvements and issues arising from distributional shifts between training and inference data.
SCoRe operates in two stages:
Initialization Stage: The model is trained to optimize correction performance while keeping its initial responses close to those of the base model. This prevents the model from deviating too much in its first attempt.
Reinforcement Learning Stage: The model undergoes multi-turn reinforcement learning to maximize rewards for both initial and corrected responses. A reward bonus is included to encourage significant improvements from the first to the second attempt.
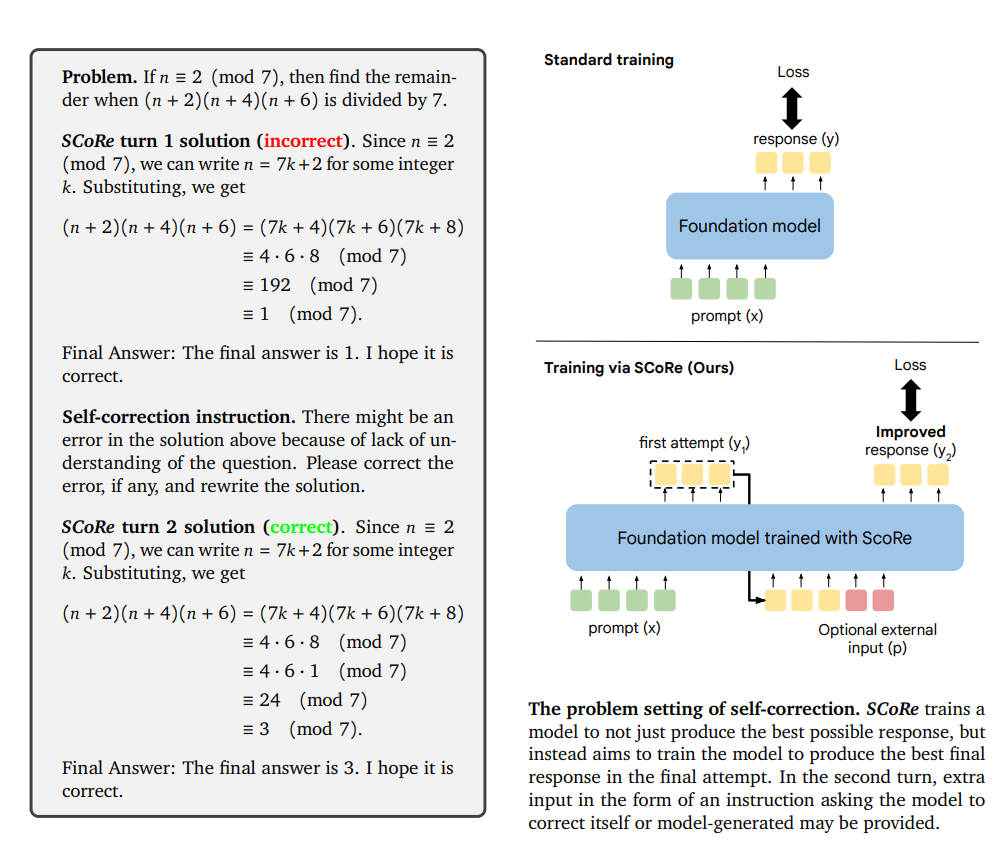
By structuring the training this way, SCoRe ensures that the model doesn't simply produce the best possible first response with minimal corrections but instead learns to meaningfully improve upon its initial answers.
The results demonstrate that SCoRe significantly enhances intrinsic self-correction abilities in LLMs.
Scaling Smart: Accelerating Large Language Model Pre-training with Small Model Initialization
Training LLMs is both expensive and time-consuming, requiring substantial computational resources.
Smaller models are less costly but often fail to deliver the desired level of accuracy, leaving industries with a dilemma. To address this, the authors introduce HyperCloning, a method that initializes large transformer models from smaller ones.
HyperCloning ensures a function-preserving transformation, meaning the output of the larger initialized model matches that of the smaller model at the start of training.

This approach enables the larger model to begin with the same accuracy as the smaller one and improves further with additional training.
Experiments demonstrate that HyperCloning enhances both training speed and final accuracy compared to traditional random initialization. The method was evaluated across three families of open-source language models—OPT, Pythia, and OLMO—showing significant improvements in accuracy and training efficiency.

Promptriever: Instruction-Trained Retrievers Can Be Prompted Like Language Models
Modern information retrieval (IR) models typically rely on a single semantic similarity score to match queries with passages, which can make the search experience opaque and require users to iteratively refine their queries or apply complex filters.
To address this limitation, the authors introduce Promptriever, a retrieval model that can be controlled via natural language prompts. Promptriever allows users to dynamically adjust the notion of relevance by providing free-form natural language instructions, such as specifying that relevant documents should meet certain criteria.
Promptriever is a bi-encoder retriever built upon LLMs. Unlike traditional IR models that lose instruction-following capabilities after standard training focused on semantic similarity, Promptriever is trained to maintain per-instance instruction-following. This is achieved by curating a synthetic dataset of approximately 500,000 query-passage pairs augmented with diverse, free-form instructions and "instruction negatives." Instruction negatives are carefully constructed cases where a passage's relevance changes significantly based on the instruction, forcing the model to adapt its relevance assessment per query.
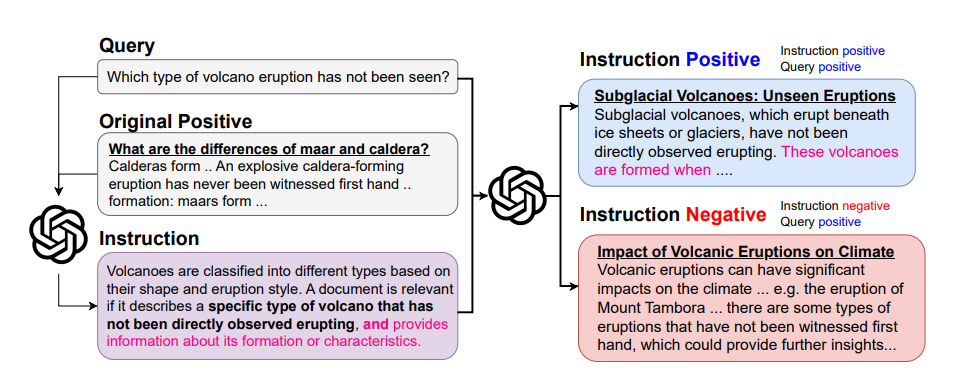
The results indicate that with appropriate training data, modern bi-encoders can be instructed using free-form natural language similarly to language models. This alignment between language modeling and information retrieval opens avenues for further improvements in dense retrieval models.
Code here:
GitHub: orionw/promptriever
If you have any questions about one of these papers, write them in the comments. I will answer them.