

Reviewed this week
Reducing Transformer Key-Value Cache Size with Cross-Layer Attention
⭐MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning
Distributed Speculative Inference of Large Language Models
Stacking Your Transformers: A Closer Look at Model Growth for Efficient LLM Pre-Training
⭐: Papers that I particularly recommend reading.
New code repositories:
I maintain a curated list of AI code repositories here:
Reducing Transformer Key-Value Cache Size with Cross-Layer Attention
Existing work has proposed various methods for decreasing the memory footprint of the KV cache, such as storing KV activations in low precision, evicting unimportant KV cache entries, and sharing keys and values across query heads in the attention mechanism.
In this paper, MIT introduces a method for reducing the size of the KV cache by focusing on a different aspect: reducing the number of unique layers in the KV cache.
They propose Cross-Layer Attention (CLA), a modification of the transformer architecture that reduces the size of the KV cache by sharing KV activations across layers.

Through pre-training experiments, they evaluate the impact of different CLA configurations on accuracy and memory usage across various architectural hyperparameters, learning rates, and model sizes.
Their findings show that CLA enables accuracy/memory Pareto improvements compared to existing Multi-Query Attention (MQA) and Grouped-Query Attention (GQA) architectures.

⭐MoRA: High-Rank Updating for Parameter-Efficient Fine-Tuning
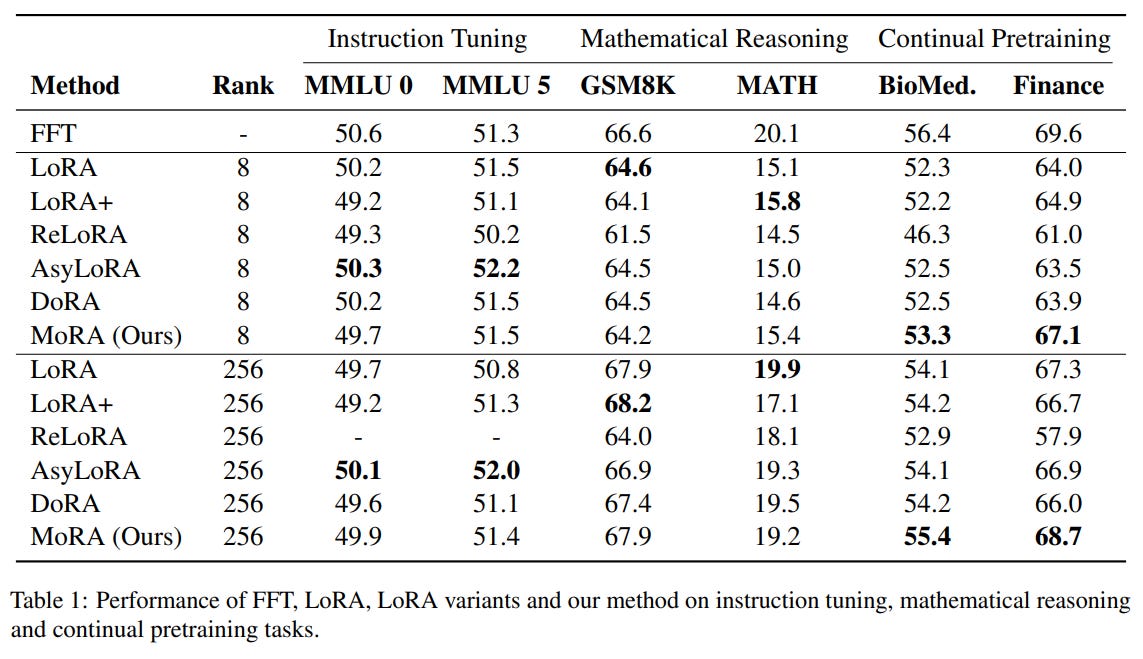
In this paper, the authors first conduct an evaluation of LoRA across various tasks under consistent settings, including instruction tuning, mathematical reasoning, and continual pre-training. They find that LoRA-like methods exhibit similar performance across these tasks, matching FFT (Full Fine-Tuning) in instruction tuning but falling short in mathematical reasoning and continual pre-training.
A plausible explanation for LoRA's limitations is its reliance on low-rank updates. The low-rank update matrix, ∆W, struggles to estimate the full-rank updates in FFT. Since the rank of ∆W is significantly smaller than the full rank, this limits its capacity to store new information via fine-tuning. Current LoRA variants cannot alter this inherent low-rank characteristic. To validate this, the authors conducted a memorization task using pseudo-data and found that LoRA performed significantly worse than FFT, even with a large rank such as 256.
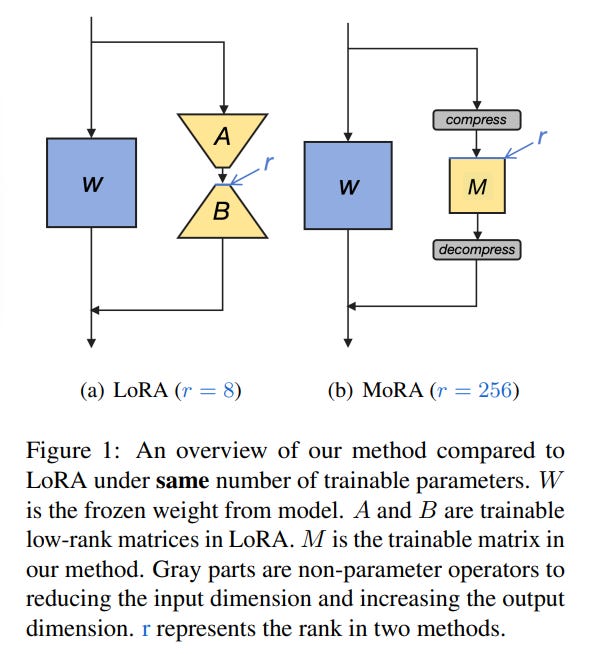
To address these issues, they introduce MoRA, which employs a square matrix instead of low-rank matrices to maximize the rank in ∆W while maintaining the same number of trainable parameters. For instance, with a rank of 8 and a hidden size of 4096, LoRA uses two low-rank matrices A ∈ R^4096×8 and B ∈ R^8×4096, resulting in rank(∆W) ≤ 8. In contrast, MoRA uses a square matrix M ∈ R^256×256, resulting in rank(∆W) ≤ 256, which increases capacity compared to LoRA. To adjust the input and output dimensions for M, corresponding non-parameter operators are developed, and these operators and M can be substituted by a ∆W, ensuring the method can integrate back into LLMs like LoRA.
The authors evaluate MoRA across five tasks: memory, instruction tuning, mathematical reasoning, continual pre-training, and pre-training. Their method outperforms LoRA in memory-intensive tasks and achieves comparable performance on other tasks, demonstrating the effectiveness of high-rank updating.
The authors published their code here:
GitHub: kongds/MoRA
I’ll publish a full review of this paper and try MoRA with Llama 3, probably this week.
Distributed Speculative Inference of Large Language Models
Recent work on accelerating LLMs' inference is based on speculative inference, where speculative execution predicts possible completions of the input prompt using faster “draft” LLMs that approximate the target LLM.
These predicted completions are then verified concurrently using CUDA-based processors, leading to faster inference. Empirical evidence shows that this approach significantly speeds up inference. Improvements in this method have introduced lossless verification techniques, leading to 2-3x speedups in decoding with LLMs with 11B and 70B parameters. In the Kaitchup, I confirmed that speculative decoding can indeed speed up inference but that also finding an optimal pair of draft-target LLMs is challenging.

Traditional speculative decoding methods, however, do not leverage multiple processing units effectively and only show acceleration when the draft LLM is highly accurate and faster than the target model. This raises two key questions: can inference time be reduced by using multiple processors simultaneously, and can it be accelerated using slower or more accurate draft LLMs?
In this paper, the authors propose the first distributed algorithm for speculative inference across multiple GPUs. It empirically validates that this method can speed up inference time. Additionally, it demonstrates that while standard speculative decoding requires a draft model that is both fast and accurate, this new method can accelerate inference time even with slower and less accurate draft models.
This is very promising. The authors plan to release the code once their paper is accepted and published by a conference/journal.
Stacking Your Transformers: A Closer Look at Model Growth for Efficient LLM Pre-Training
Model growth focuses on leveraging parameters from smaller trained models to initialize larger models, aiming to accelerate the training of large models. Despite promising speedup in training, model growth methods are not widely adopted for LLM pre-training.
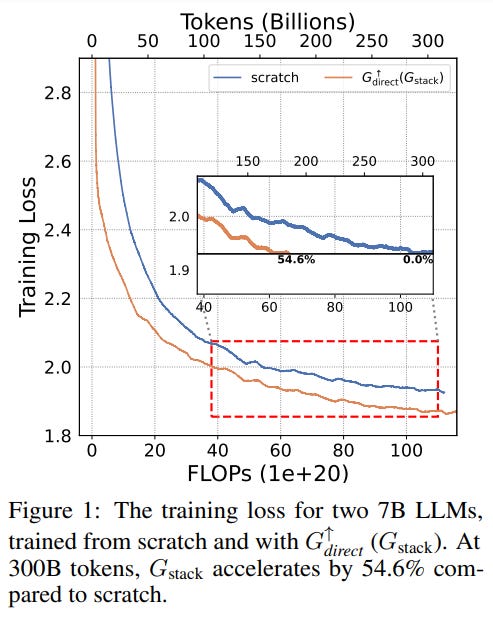
The authors of this paper revisit model growth for efficient LLM pre-training. They categorize existing growth methods into four atomic growth operators, each expanding models either widthwise or depthwise. These operators are used to expand 400M base models to 1.1B Llama-like LLMs, which are then continually pre-trained.
Evaluation on training loss and NLP benchmarks shows that the depthwise stacking operator, Gstack, consistently outperforms others, demonstrating its potential in accelerating LLM pre-training.
If you have any questions about one of these papers, write them in the comments. I will answer them.