

Reviewed this week
⭐On Speculative Decoding for Multimodal Large Language Models
Reuse Your Rewards: Reward Model Transfer for Zero-Shot Cross-Lingual Alignment
Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
⭐: Papers that I particularly recommend reading.
New code repositories:
No new repository this week
I maintain a curated list of AI code repositories here:
On Speculative Decoding for Multimodal Large Language Models
In this short paper, Qualcomm experiments with speculative decoding using the LLaVA 7B model to improve multimodal inference efficiency.

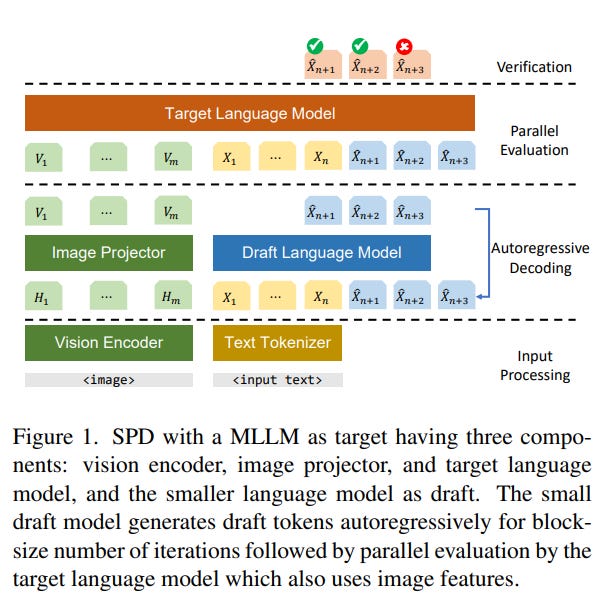
Due to the unavailability of smaller LLaVA and Llama models, a new 115M parameter language model was developed for this purpose. The research demonstrates that a language-centric model, which excludes image tokens and thus does not need an image encoder and adapter, effectively serves as an initial draft model for LLaVA 7B.
Experiments were conducted across three tasks: image QA on the LLaVA Instruct 150K dataset, image captioning on the Coco dataset, and the ScienceQA dataset.
These experiments used draft model candidates at various stages of training and fine-tuning. The findings indicate that using a language model as a draft model can lead to a speedup of up to 2.37 times. Additionally, a smaller draft model combining an image adapter with the language model was created, which showed slight improvements in performance on the COCO captioning and ScienceQA tasks, while maintaining comparable performance to language-only draft models on other tasks.
Reuse Your Rewards: Reward Model Transfer for Zero-Shot Cross-Lingual Alignment
Alignment is a crucial process in adapting LLMs to align with human preferences. In the Kaitchup, I have presented several techniques for preference optimization:



However, this process presents challenges, particularly in acquiring labeled preference data for many languages, which is often costly compared to the readily available multilingual unlabeled data used in autoregressive language modeling.
This paper introduces an approach where a reward model (RM) developed for one language is repurposed to align an LLM in a different language. This method was tested across two tasks—summarization and open-ended dialog generation—using two optimization strategies: reinforcement learning and best-of-n reranking.

The findings reveal that this cross-lingual application of RMs can sometimes surpass the performance of using an RM trained in the same language.
This was observed even in scenarios where data for supervised fine-tuning is unavailable in the target language. The study demonstrates the robustness and generalizability of RM signals to changes in input distributions.
Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
The paper presents ALPHALLM, a framework designed for the self-improvement capabilities of LLMs through an imagination-searching-criticizing approach.
This framework comprises three main components:
An imagination component that generates prompts to address data scarcity
An efficient search strategy named ηMCTS (Monte Carlo Tree Search) for language tasks
A trio of critic models for precise feedback
The ηMCTS treats text generation as a series of options within a Markov Decision Process, akin to chain-of-thought prompting, which helps reduce search depth significantly. To optimize the search process further, the framework uses techniques like state fusion and adaptive branching factors to balance search breadth and depth.
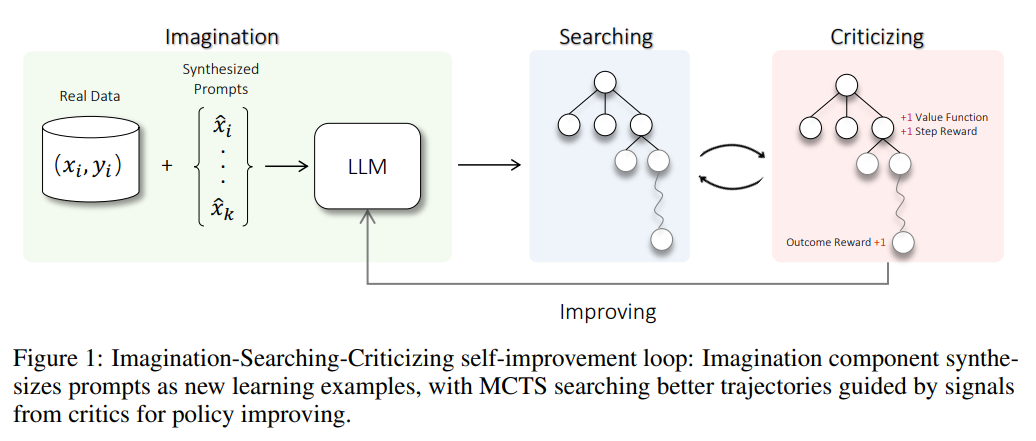
Critically, for effective MCTS, the framework includes a value function, a process reward model, and an outcome reward model. These models provide dynamic and accurate feedback, especially useful for tasks like arithmetic computation and code execution that are typically challenging for LLMs. The feedback from these models informs the training for the next iteration of LLM improvement.
Experimental results, particularly in mathematical reasoning tasks, show that ALPHALLM significantly boosts the performance of the Llama 2 70B model, raising its effectiveness on the GSM8K and MATH datasets to levels comparable with GPT-4.
If you have any questions about one of these papers, write them in the comments. I will answer them.