For this first issue of 2025, I only reviewed two papers:
⭐Understanding and Mitigating Bottlenecks of State Space Models through the Lens of Recency and Over-smoothing
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
⭐: Papers that I particularly recommend reading.
New code repositories (list of all repositories):
No new code repository this week.
While I’m starting to doubt the possibility of SSMs fully replacing Transformers, given the continuous optimization and dominance of Transformer architectures, SSMs still offer valuable innovations that can be integrated into Transformers to enhance their efficiency and performance.
For instance, this paper explores the evolution and challenges of sequence processing architectures, focusing on State Space Models (SSMs) as an alternative to transformers. SSMs have efficient handling of long sequences through convolutional and recurrent modes, leveraging hardware-optimized convolutions for parallel processing and compact hidden states for memory efficiency. They enable long-term memory with simplified state matrices that improve computational efficiency while capturing long-range dependencies. But challenges persist.
Recency Bias: SSMs heavily prioritize nearby context, limiting their ability to model long-range dependencies. This bias persists even with advanced selection mechanisms like Mamba.
Memory Loss for Long Contexts: Mamba struggles with distant content retrieval when context length exceeds its memory capacity.
Robustness Issues: SSMs are vulnerable to adversarial attacks on local tokens due to their recency bias.
Over-smoothing in Deep Architectures: As SSM depth increases, token representations become uniform, reducing distinguishability and performance.
To address these issues, the paper introduces a polarization technique, which dedicates two channels in SSM state transition matrices:
An all-one channel preserves historical information, preventing forgetting.
A zero channel slows smoothing, avoiding excessive fusion of past information.
Experiments show that polarization mitigates recency bias, improves recall accuracy, and enhances performance in deeper architectures by alleviating over-smoothing. These findings suggest a unified framework for addressing the fundamental trade-off between recency and long-range dependency modeling in SSMs.
The authors plan to release their code here (not yet available):
GitHub: VITA-Group/SSM-Bottleneck
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
This is one more interesting paper about the token budget allocated to LLMs for “reasoning”.
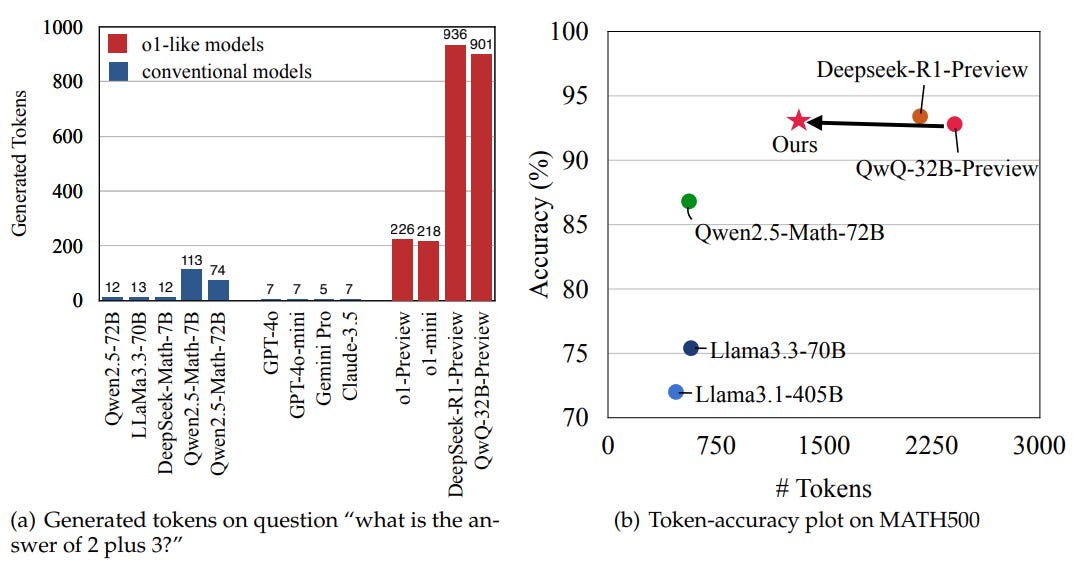
This study explores the inefficiency of state-of-the-art AI reasoning models like OpenAI’s o1, which adopt a long chain-of-thought (CoT) approach during inference to handle complex reasoning tasks. While this “scaling test-time compute” approach improves accuracy, it reveals significant “overthinking” issues. These models often overallocate computational resources to simple problems or questions with evident answers, generating redundant solutions that contribute minimally to accuracy. For instance, o1-like models consumed 1,953% more tokens than conventional models for a basic arithmetic question.
The findings highlight that overthinking in o1-like models leads to inefficiencies, lacks diversity in reasoning strategies, and occurs more frequently with simpler problems. The complexity of computation is mismatched with the problem’s requirements.
The study proposes two new efficiency metrics to address these inefficiencies and assess models from both outcome and process perspectives. A self-training paradigm was also developed to streamline responses by removing redundant solutions while preserving essential reasoning. Experiments demonstrated the effectiveness of this approach, achieving significant reductions in token output (e.g., a 48.6% decrease on the MATH500 test set) without degrading accuracy.