The Ultimate Recipe to Defeat Prompt Injections?
The Weekly Salt #61


This week, we read:
⭐Defeating Prompt Injections by Design
Variance Control via Weight Rescaling in LLM Pre-training
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
⭐: Papers that I particularly recommend reading.
I’m currently writing the next deep dive for The Salt. It will focus on the (lack of) evaluation of GGUF models. Despite being one of the most popular formats for deploying LLMs, GGUF models are rarely evaluated on downstream tasks. We'll explore just how well these models actually perform and dig into potential reasons behind the scarcity of evaluations. Spoiler: if you’re using GPUs and aiming for performance close to the original model, GGUF-quantized models are definitely not your best option!
New code repositories (list of all repositories):
The Salt - Curated AI is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
I'm currently offering a 30% discount on the annual subscription
⭐Defeating Prompt Injections by Design
LLMs are increasingly used in agentic systems that interact with external environments through APIs and user interfaces. This makes them vulnerable to prompt injection attacks, where malicious instructions from untrusted sources (like users or web pages) are inserted into the LLM's context to exfiltrate data or trigger harmful actions.
Current defenses often rely on prompting or training models to follow security policies, which are typically fragile and implemented in system prompts. These are inadequate due to the lack of robust, formal enforcement mechanisms.
This paper introduces CaMeL (Capabilities for Machine Learning), a new defense system inspired by traditional software security principles such as Control Flow Integrity, Access Control, and Information Flow Control. CaMeL:
Tracks data and control flows from user queries;
Attaches metadata (capabilities) to each value to define fine-grained security policies;
Leverages a custom Python interpreter to enforce security policies in a sandboxed environment, aligning with common practices in agentic pipelines, where full-fledged sandboxes are increasingly standard, while notably achieving this without requiring any modifications to the underlying LLM.

CaMeL is integrated into the AgentDojo benchmark for evaluating agentic system security, where it successfully prevents prompt injection attacks by design.
Variance Control via Weight Rescaling in LLM Pre-training
Stable neural network training relies heavily on carefully designed weight initialization schemes to maintain proper gradient flow. However, weights often diverge during training from their initial scale, leading to issues like reduced generalization and unstable optimization. This is particularly problematic in Transformer-based LLMs, where training is resource-intensive and variance control has been underexplored.
While techniques like LayerNorm, RMSNorm, and weight decay help stabilize training, they can mask the underlying problem of unbounded weight growth. To address this, the paper introduces two key strategies:
Layer Index Rescaling (LIR): A weight initialization method that adjusts scaling based on layer depth.
Target Variance Rescaling (TVR): A training-time variance control strategy that helps maintain consistent weight distributions.
The experiments conducted by the authors on a 1B parameter LLaMA model show that managing weight variance at both initialization and during training improves downstream performance, and helps with quantization(!) and low-precision training by reducing extreme activation values.

That’s some very interesting findings! If it can be confirmed at a larger scale, e.g., with 7B+ LLMs, these techniques could be widely adopted.
They released their code here:
GitHub: bluorion-com/weight_rescaling
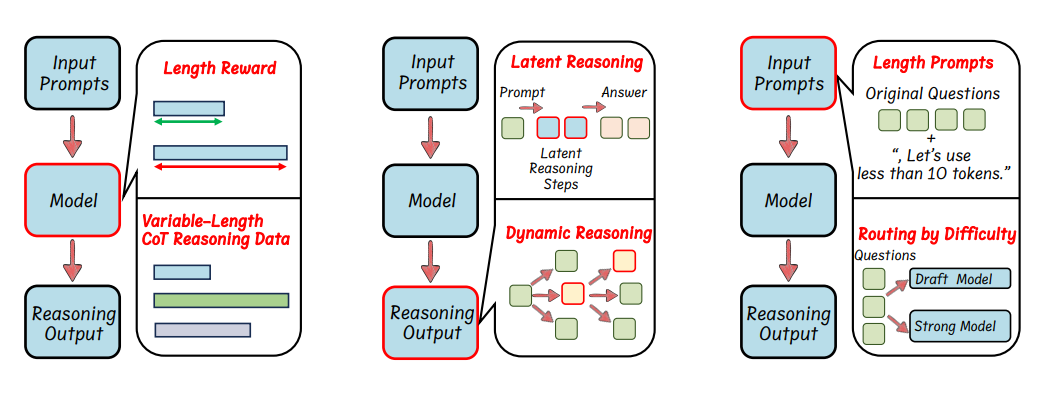
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Large Reasoning Models (LRMs), such as OpenAI o1 and DeepSeek-R1, often rely on Chain-of-Thought (CoT) prompting to generate step-by-step reasoning. While this approach significantly boosts accuracy in reasoning-heavy tasks, it also introduces a major drawback: excessive verbosity. This so-called "overthinking problem" results in unnecessarily long outputs, even for simple queries, increasing inference cost and latency. Such inefficiencies make these models less practical for real-time or computation-sensitive applications.
Recent research has shifted toward efficient reasoning, which aims to preserve reasoning quality while reducing output length. We saw several of these papers in the previous Weekly Salt.
This involves refining how models are trained, how reasoning outputs are structured during inference, and how prompts are designed to guide concise reasoning. Efficient reasoning differs from traditional model compression techniques by focusing on optimizing the reasoning process itself, rather than just reducing model size.
This paper provides one of the first comprehensive surveys of this growing field, categorizing approaches by how they influence model behavior, output structure, and prompt design. It also explores related topics such as the reasoning abilities of smaller models, training with efficient data, and benchmarking for efficiency.