


Reviewed this week:
Multi-Layer Transformers Gradient Can be Approximated in Almost Linear Time
FocusLLM: Scaling LLM's Context by Parallel Decoding
⭐Jamba-1.5: Hybrid Transformer-Mamba Models at Scale
LLM Pruning and Distillation in Practice: The Minitron Approach
⭐: Papers that I particularly recommend reading.
New code repositories:
No new code repository made it to the list this week.
I maintain a curated list of AI code repositories here:
Multi-Layer Transformers Gradient Can be Approximated in Almost Linear Time
One of the LLMs’ key strengths is handling long-context information, which is crucial for tasks like summarizing long documents or maintaining extended conversations. However, the self-attention mechanism, which is central to LLMs using the transformer architecture, becomes a bottleneck when dealing with long contexts due to its quadratic time complexity.
This work introduces an approximation of the back-propagation of self-attention in almost linear time, significantly reducing the resources needed for training LLMs. By leveraging the sparsity in the dense attention matrices, this approach accelerates computations and can be applied to any gradient-based algorithm.
This new method not only addresses the quadratic bottleneck but also integrates seamlessly with existing techniques to improve their performance.
However, while the theory of what they proposed seems to hold, they don’t provide empirical proof yet.
Note: The paper itself is long and complex. I only recommend reading it if you have a strong mathematical background.
FocusLLM: Scaling LLM's Context by Parallel Decoding
Increasing context length presents challenges such as high computational costs, poor performance on longer sequences, and difficulty in acquiring quality long-text datasets.
To address these issues, the paper introduces FocusLLM, a training-efficient solution that enables LLMs to focus on relevant content within long documents. FocusLLM adapts any decoder-only language model by freezing original parameters and adding a small number of trainable ones for parallel decoding, allowing it to handle much longer texts without losing accuracy.

FocusLLM has three main advantages: it breaks positional limitations to handle significantly longer texts, it is training-efficient with a minimal training budget, and it seems good in both language modeling and specific tasks like question answering.

They plan to release their code here (empty repository when I wrote this):
GitHub: leezythu/FocusLLM
⭐Jamba-1.5: Hybrid Transformer-Mamba Models at Scale
I wrote about Jamba 1.5 last week, in The Weekly Kaitchup. I think it’s also a very good paper to read.
Jamba-1.5 includes two new large language models built on the Jamba architecture.

Jamba-1.5 Mini and Large are an improved instruction-tuned version of the previous Jamba model. Jamba-1.5-Large stands out with 94 billion active parameters (out of 398 billion total), and despite its size, it is efficient enough to run on a single machine with 8 GPUs.
LLM Pruning and Distillation in Practice: The Minitron Approach
This article is a follow-up to this one:
Compact Language Models via Pruning and Knowledge Distillation
This report applies the Minitron compression strategy to two models: Llama 3.1 8B and Mistral NeMo 12B, compressing them to 4B and 8B parameters, respectively. A key modification in this process involves fine-tuning the teacher model on a custom dataset, termed "teacher correction," to address data distribution mismatches that could negatively impact distillation.
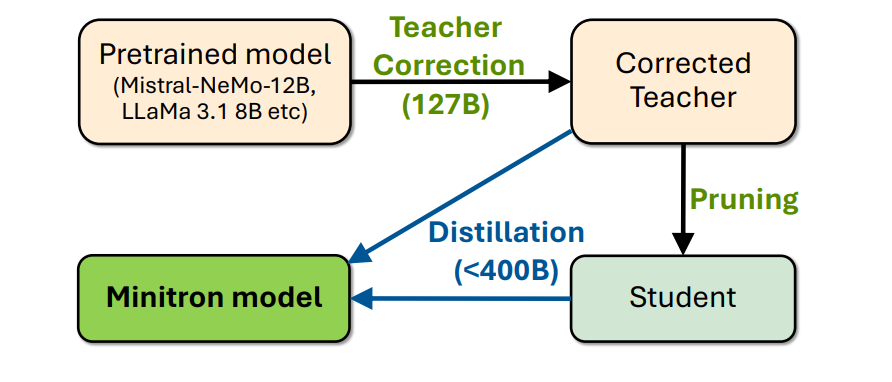
The results show that the compressed models outperform all similarly-sized models on standard benchmarks. Additionally, these compressed models achieve significant runtime speedups during inference, with the MN-Minitron-8B model being 1.2× faster than the Mistral NeMo 12B, and the Llama-3.1-Minitron-4B models achieving 2.7× and 1.8× speedups for depth and width-pruned variants, respectively.
I wrote about how to quantize Minitron, yesterday, in The Kaitchup.
If you have any questions about one of these papers, write them in the comments. I will answer them.