


Towards Token-Free LLMs?
The Weekly Salt #2


In The Weekly Salt, I review and analyze in plain English interesting AI papers published last week.
Reviewed this week
MambaByte: Token-free Selective State Space Mode
West-of-N: Synthetic Preference Generation for Improved Reward Modeling
⭐APT: Adaptive Pruning and Tuning Pretrained Language Models for Efficient Training and Inference
Knowledge Fusion of Large Language Models
MaLA-500: Massive Language Adaptation of Large Language Models
⭐: Papers that I particularly recommend reading.
New code repository
I maintain a curated list of AI code repositories here:
MambaByte: Token-free Selective State Space Mode
This research by Cornell University introduces MambaByte, a token-free language model learned directly from raw bytes and derived from the Mamba architecture.
Mamba uses a linear-time approach for sequence modeling that is suitable to train LLM on byte sequences which would be much longer than their standard tokenized equivalent.
Experimental comparisons are conducted between MambaByte and Transformers, among other architectures, in a fixed parameter and fixed compute setting across various long-form text datasets.
The findings indicate that MambaByte outperforms byte-level Transformers in terms of both speed and compute efficiency.
The results position MambaByte as a robust alternative to existing tokenizer-dependent models.
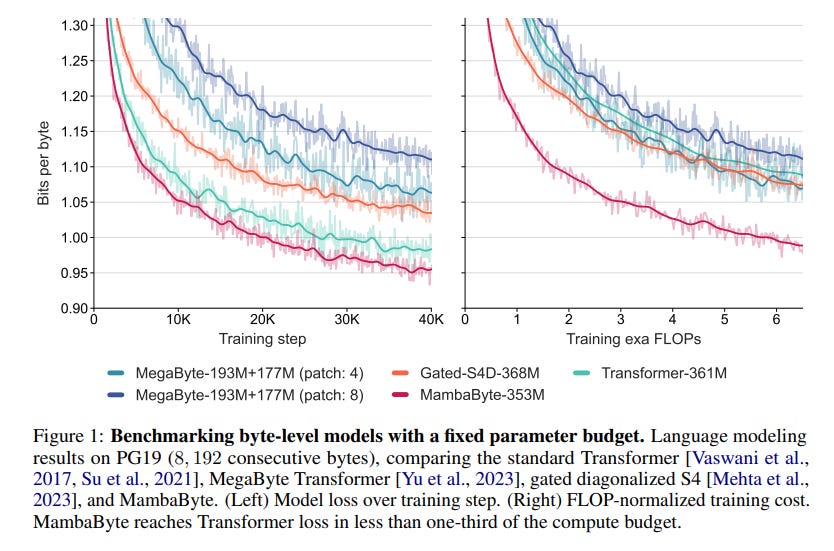
The idea is original and well-formalized, however, if you read the current version of the paper, take the evaluation results (Section 4) with a pinch of salt. Many numbers are copied and compared from different papers. I could not confirm that all these numbers are truly comparable. I assume that they are not since we usually don’t know the complete experimental settings under which the copied numbers were calculated.
West-of-N: Synthetic Preference Generation for Improved Reward Modeling
This study presents a novel approach to enhance reward model (such as the one used in RLHF) training by generating high-quality synthetic preference data. Leveraging the language model generative capabilities, this method establishes a semi-supervised training framework.

The approach centers on Best-of-N sampling, a strategy generating N outputs and selecting the best-scored one based on a reward model. Although proven effective in language model training, this sampling technique remains unexplored for reward model training. The researchers extend it to this context to improve preference modeling and language model alignment.
Utilizing West-of-N sampling, synthetic preference data is generated by extracting the best and worst generations among N outputs for a specific unlabeled prompt. This self-training method simply and effectively augments the initial preference dataset with high-quality chosen (the best) vs. rejected (the worst) preferences (outputs), leading to substantial improvements in reward modeling performance.

⭐APT: Adaptive Pruning and Tuning Pretrained Language Models for Efficient Training and Inference
This paper introduces APT, an adaptive fine-tuning approach that efficiently selects model parameters for pruning and fine-tuning, combining the advantages of parameter-efficient fine-tuning (PEFT) and structured pruning.
APT capitalizes on the notion that pre-trained LLM parameters contain general knowledge, with varying importance to downstream tasks. By removing irrelevant parameters early in the training stage, APT enhances both training and inference efficiency without significantly compromising model accuracy.
APT removes irrelevant LLM parameter blocks and adds more tuning parameters based on layer importance during fine-tuning. Combined with a self-distillation technique that shares teacher and student parameters, APT achieves accurate LLM pruning with reduced training time and lower memory usage.
Experimental results demonstrate APT's efficiency, pruning RoBERTa and T5 base models 8× faster than the LoRA + pruning baseline while achieving 98.0% of its performance with a 2.4× speedup and 78.1% memory consumption during inference. When applied to large LLMs like Llama 2, APT maintains 86.4% of the performance with 70% parameters.
Knowledge Fusion of Large Language Models
This paper tackles the challenge of LLM fusion, introducing FUSELLM, which employs lightweight continual training to align tokenizations and fuse probability distributions. The focus during training is on minimizing divergence between the target LLM and source LLMs.
Their empirical evaluations on three prominent open-source LLMs—Llama-2, OpenLLaMA, and MPT—show that their fusion yields better results across 42 tasks, spanning reasoning, commonsense, and code generation.

FUSELLM is also better than ensemble and weights merging.
The authors released the code here:
MaLA-500: Massive Language Adaptation of Large Language Models
This research seeks to expand the language capabilities of existing LLMs to include particularly low-resource languages.
While existing works have addressed language adaptation for smaller model sizes, this study extends this exploration to LLMs with parameters scaling up to 10 billion.
Their approach involves continued pretraining, specifically Llama 2 (spelled “LLaMA 2” in this work…), vocabulary extension, and adaptation techniques like LoRA to teach the new language to the LLMs. One of the main outcomes is MaLA-500, a model covering over 500 languages across various domains.
The evaluation of MaLA-500 on the SIB-200 dataset demonstrates superior performance compared to existing open LLMs of similar or slightly larger model sizes.
If you have any questions about one of these papers, feel free to write them in the comments. I’ll answer them.