


Reviewed this week:
ShadowKV: KV Cache in Shadows for High-Throughput Long-Context LLM Inference
⭐Stealing User Prompts from Mixture of Experts
TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters
⭐: Papers that I particularly recommend reading.
New code repositories (list of all repositories):
TokenFormer: Transformer with Tokenized Model Parameters
ShadowKV: KV Cache in Shadows for High-Throughput Long-Context LLM Inference
LLMs are now capable of handling long contexts of million tokens, which is essential for complex tasks like multi-document question answering. However, managing these long-context models efficiently is challenging due to the substantial memory footprint and reduced throughput caused by the growing key-value (KV) cache, which stores previous computations for each token. Existing methods like KV cache eviction, quantization, and sparse attention attempt to address these issues but often compromise on memory efficiency or model accuracy.

This paper introduces ShadowKV, a high-throughput system that optimizes memory use and decoding speed for long-context LLM inference. The approach is based on two main insights:
Low-Rank Keys and Offloaded Values: The model uses low-rank decomposition for the key cache (pre-RoPE keys), which is retained on the GPU to save memory while offloading the non-compressible value cache to the CPU. This setup reduces the memory footprint without losing accuracy. During decoding, CUDA multi-streams coordinate the fetching of necessary values from the CPU with GPU-based key cache reconstruction, cutting data-fetching overhead by half.
Accurate KV Selection for Fast Decoding: ShadowKV identifies important tokens using chunk-level approximations, as most post-RoPE keys share similarities with neighboring tokens. By focusing on these relevant chunks, ShadowKV minimizes sparse attention budgets while maintaining high accuracy. A small number of outlier tokens are kept on the GPU to preserve model precision.
Using these techniques, ShadowKV selects relevant KV pairs for high-speed decoding. Experiments with various LLMs, such as Llama and GLM, show that ShadowKV supports larger batch sizes (up to 6x) and increases throughput by over 3x on long-context tasks without compromising accuracy. The method also achieves superior sparsity and decoding speeds compared to other sparse attention methods.

Stealing User Prompts from Mixture of Experts
Mixture-of-Experts (MoE) architectures have become popular in LLMs. MoE models distribute processing across multiple "expert" modules, selectively activating only the required experts for each input. This selective activation boosts efficiency. However, this setup seems to also introduce certain vulnerabilities.

A recent study by Hayes et al. (2024) identified a security issue in MoE models related to "token dropping," which occurs when an expert’s capacity is exceeded, causing some tokens to be discarded or rerouted. An attacker who strategically places their data in the same batch as the victim’s can exploit this, overflowing the expert buffers and causing a Denial-of-Service (DoS) attack that affects the victim’s model response quality.
This paper expands on that vulnerability by presenting a new, more serious attack called "MoE Tiebreak Leakage." This attack exploits the token-dropping phenomenon to leak private user inputs. An attacker can craft inputs to influence expert routing and leak the victim’s prompt by creating a cross-batch side channel. This vulnerability particularly affects models using Expert Choice Routing (ECR), which allows the attacker to manipulate routing to reveal the victim’s data strategically.

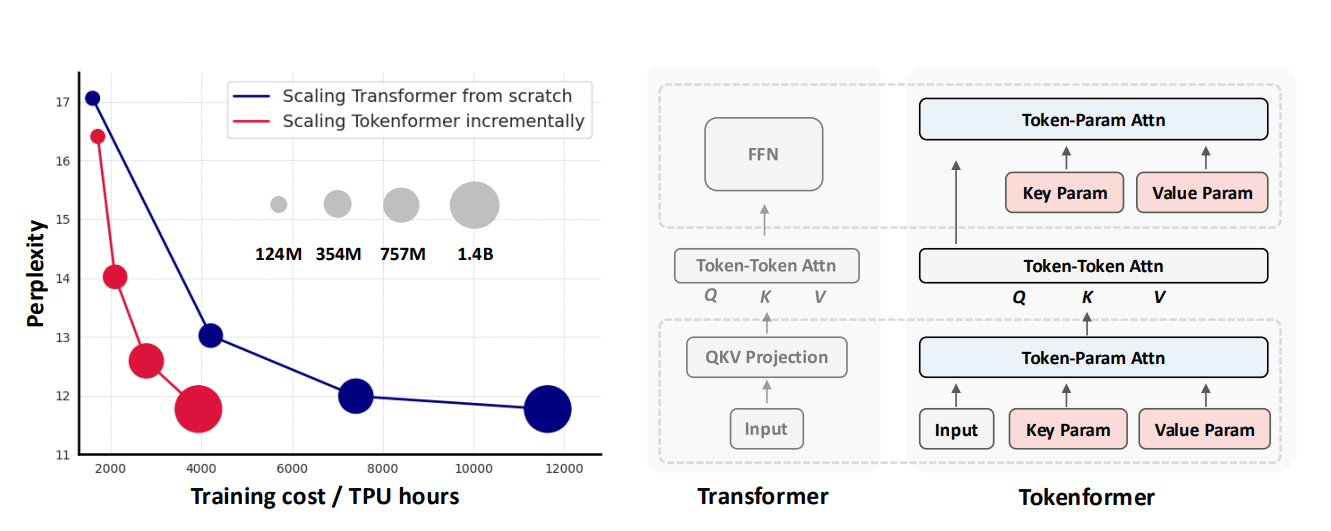
TokenFormer: Rethinking Transformer Scaling with Tokenized Model Parameters
Transformers process data through two main computational parts: token-token interactions and token-parameter interactions. Token-token interactions involve the model analyzing relationships between input tokens (data units, such as words or pixels), managed by the attention mechanism.
Token-parameter interactions, on the other hand, involve computations between the input tokens and the model's fixed parameters. Typically, these computations use linear projections, where each token is multiplied by a set of predetermined parameters. Although effective, this design limits scalability. As model sizes increase, expanding the linear projection layers becomes complex as it often requires substantial architectural changes and extensive retraining, which consumes resources and limits practical scalability.
To address these challenges, this paper introduces Tokenformer, a new architecture that improves flexibility in token-parameter interactions. Unlike the standard approach, Tokenformer unifies the token-token and token-parameter computations under a single attention mechanism, allowing it to scale incrementally without complete retraining. This can significantly reduce the computational and financial costs typically associated with scaling large models.
Tokenformer builds on the Transformer architecture but redefines its token-parameter interactions through a cross-attention mechanism. In this setup, input tokens act as "queries," while model parameters serve as "keys" and "values," allowing Tokenformer to handle variable numbers of parameters. This new approach enables efficient expansion by adding new key-value parameter pairs instead of modifying core components, making scaling more practical. For instance, this design allows Tokenformer to scale smoothly from 124 million parameters to 1.4 billion parameters, maintaining competitive performance while reducing training costs by over 50%.
The authors released their evaluation pipeline and inference code:
GitHub: Haiyang-W/TokenFormer