


Griffin and Hawk: Local Attention for Efficient Language Models
The Weekly Salt #7

In The Weekly Salt, I review and analyze interesting AI papers published last week in plain English.
Reviewed this week
⭐Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
FuseChat: Knowledge Fusion of Chat Models
Towards Optimal Learning of Language Models
When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method
⭐: Papers that I particularly recommend reading.
New code repository:
I maintain a curated list of AI code repositories here:
⭐Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
While transformer models have achieved remarkable success, their efficiency decreases when handling longer sequences due to the quadratic complexity associated with global attention mechanisms.
This complexity, along with the linear increase in the size of the key-value (KV) cache as sequence length grows, results in slower inference times. Although multi-query attention (MQA) has somewhat alleviated this problem by reducing the cache size, the growth of the cache size in relation to sequence length remains linear.
Recurrent language models, which update a fixed-size hidden state iteratively to encapsulate the entire sequence, offer a promising solution. That’s what also motivates the development of new model architectures such as RWKV.

Nevertheless, for these models to serve as viable alternatives to transformers, they must not only deliver comparable scaling performance but also match the efficiency of hardware usage.
This work introduces the RG-LRU layer, a new type of gated linear recurrent layer. Based on this layer, they developed a new recurrent block intended to replace MQA.
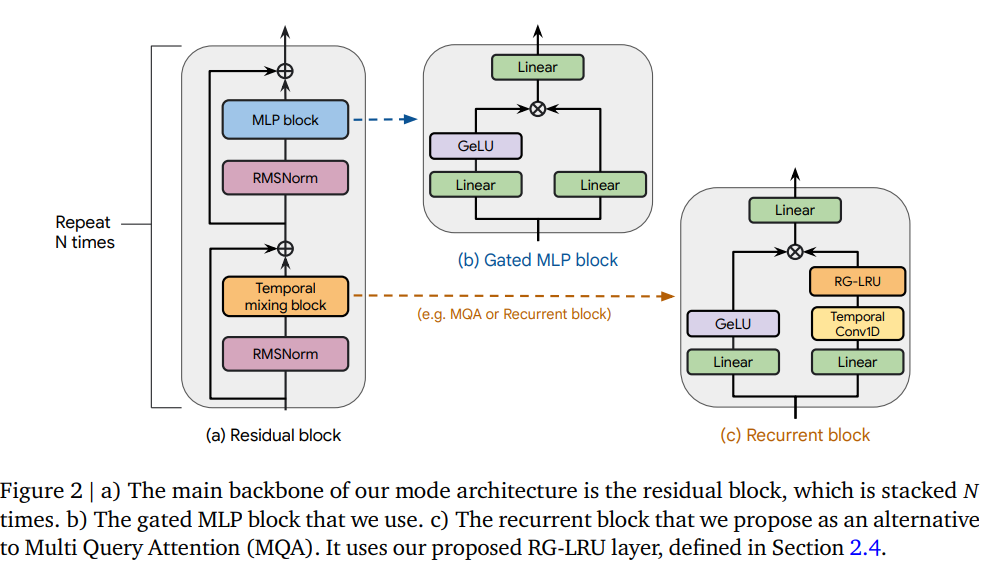
They have tested it with two new models: Hawk and Griffin. Hawk combines multi-layer perceptrons (MLPs) with the new recurrent blocks, while Griffin integrates MLPs with a blend of recurrent blocks and local attention mechanisms.
Their findings show that both models demonstrate advantageous scaling behaviors, efficient training, and superior inference capabilities compared to existing transformer models, particularly in handling extended sequences and specific tasks such as copying and information retrieval.
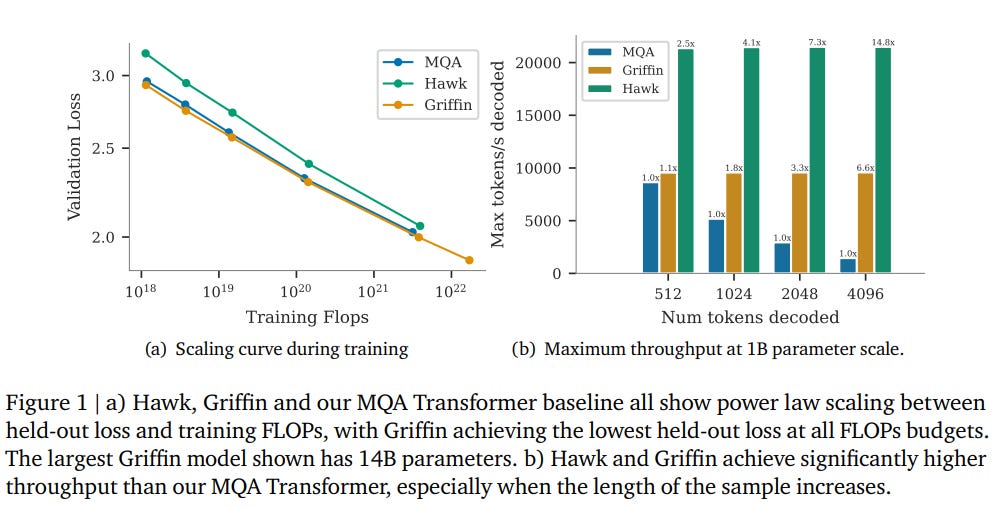
Despite these strengths, Hawk and Griffin show slightly weaker performance on certain pre-trained tasks without fine-tuning compared to Transformers.
There is a lot to unpack from this paper. I really recommend reading it.
FuseChat: Knowledge Fusion of Chat Models
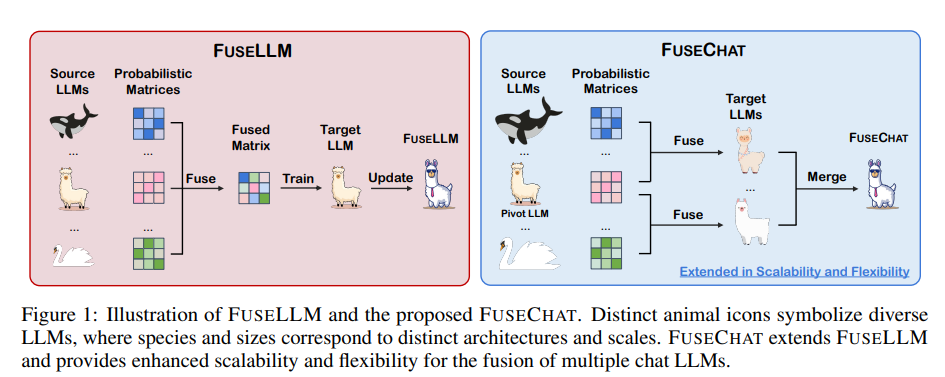
This is a follow-up work by the same team who proposed FuseLLM that I presented in the Weekly Salt #2:

This study follows the same approach as FuseLLM but applies it to chat (instruct) LLMs. This is FuseCHAT. It effectively integrates multiple chat language models of various architectures and sizes into a unified model. FuseCHAT works in two phases:
The first phase involves the knowledge fusion of source LLMs to produce several target LLMs with uniform structure and size, utilizing a pairwise fusion strategy inspired by FuseLLM.
The second phase merges these target LLMs in the same parameter space, leveraging their combined expertise and strengths.
To merge these models effectively, FuseCHAT introduces a new technique called Variation Ratio Merge (VARM), which automatically assigns weights to parameters based on their variability pre and post fine-tuning, allowing for a more nuanced integration without extra training requirements.
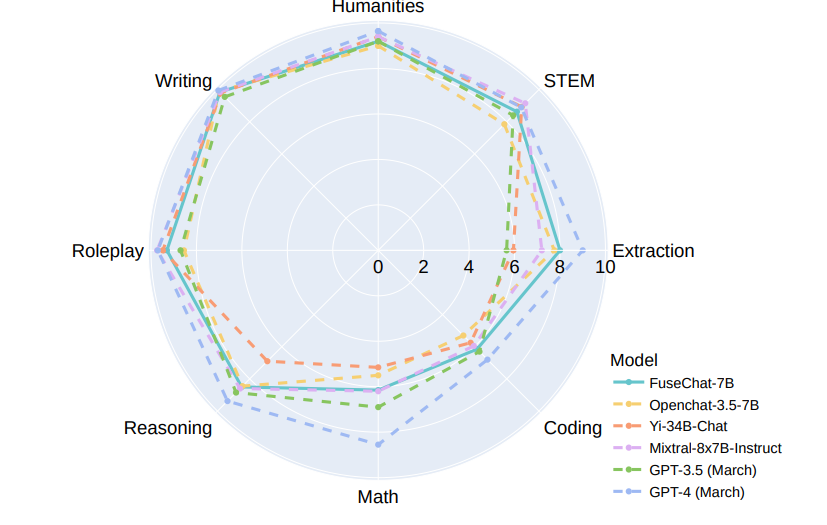
To validate FuseCHAT's performance, they tested it with three different open-source chat LLMs: NH2-Mixtral-8x7B, NH2-Solar-10.7B, and OpenChat-3.5-7B. They showed that FuseCHAT surpasses the individual source models and other baseline models at scales of 7B and 10.7B. Notably, FuseCHAT's performance was on par with the most advanced 8x7B MoE source model.
They have released their code here:
I tried it to merge several 2B (or smaller) LLMs (TinyLlama, Qwen1.5 1.8B, and Gemma 2B). While the code seems to work, FuseChat appears extremely costly to run, even for 2B models.
Towards Optimal Learning of Language Models
This paper introduces a theory for accelerating the learning process of LLMs through an approach that includes defining the optimization objective and understanding optimal learning dynamics.
The authors propose minimizing the area under the loss curve (AUC) as the optimization objective. They demonstrate that a learning process with the smallest loss AUC converges rapidly to a lower number with enough training steps.
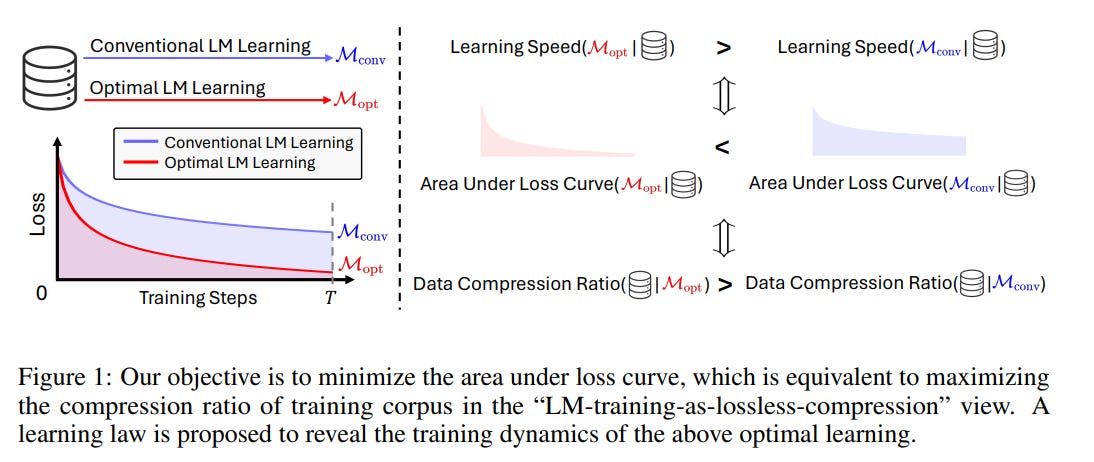
Furthermore, the authors introduce the "Learning Law," a theorem that describes the optimal dynamics of the LM learning process under this theory.
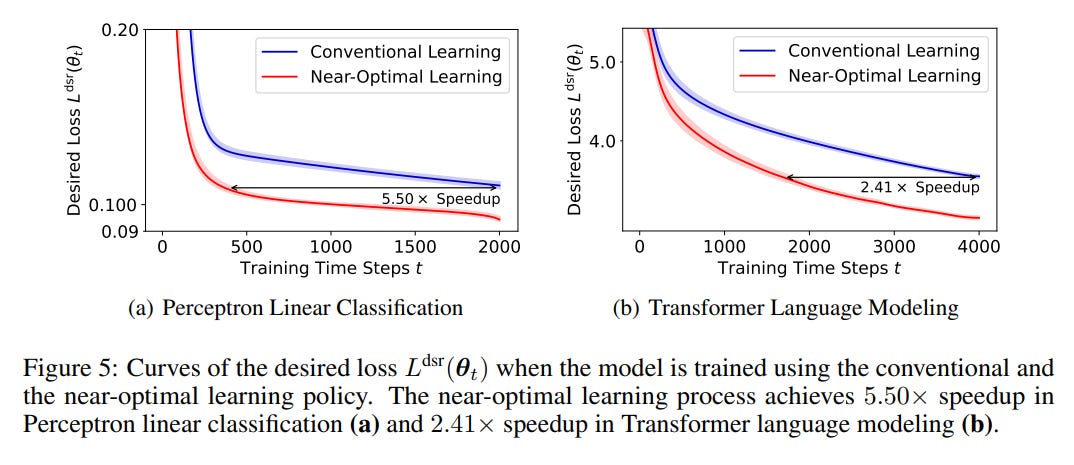
The paper validates its theoretical framework through experiments conducted on linear classification tasks and language modeling tasks using the Transformer architecture. The research team developed a gradient-based method to identify the optimal learning policy that aligns with their proposed objective. They confirmed that the learning dynamics resulting from this near-optimal policy are consistent with the "Learning Law" they introduced. It also achieves a significant acceleration of the model training.
This paper is interesting but it requires a solid knowledge of machine learning to be understood.
When Scaling Meets LLM Finetuning: The Effect of Data, Model and Finetuning Method
The fine-tuning of LLMs can be influenced by various factors, including the size of the LLM, the specific downstream task for which it is fine-tuned, the amount of fine-tuning data, and the chosen fine-tuning techniques. Despite extensive research into LLM pre-training and the development of efficient fine-tuning methods, the impact of scaling these factors during fine-tuning has been somewhat overlooked.
This paper investigates how fine-tuning performance scales, focusing on two primary methods: Full-Model Tuning (FMT), which updates all parameters of the LLM, and Parameter-Efficient Fine Tuning (PEFT), which adjusts only a small subset of parameters or introduces new ones, such as in prompt tuning and low-rank adaptation.
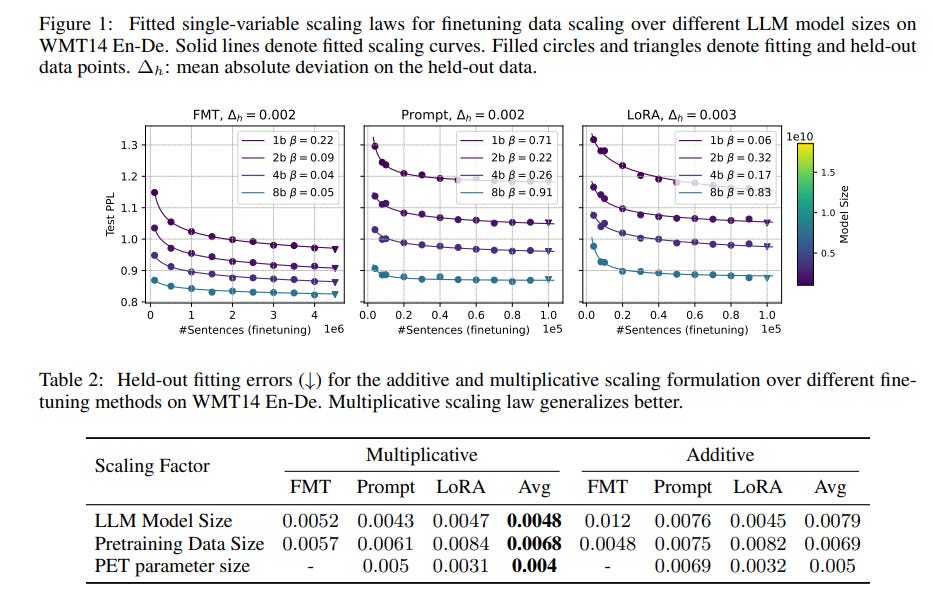
They particularly consider scenarios where fine-tuning data is scarce relative to the model size, reflecting common challenges in current LLM applications. Through experiments with bilingual LLMs in English/German and English/Chinese, and extensive testing on machine translation and multilingual summarization tasks, they have found a multiplicative joint scaling law for LLM fine-tuning that takes into account various scaling factors and demonstrates that this law holds across different contexts.
Moreover, they found out that scaling up the LLM model itself tends to have a more significant impact on fine-tuning success than increasing pre-training data size.
Fine-tuning with LLMs can enhance zero-shot generalization to related tasks, with PEFT methods outperforming FMT in such scenarios.
If you have any questions about one of these papers, write them in the comments. I will answer them.