


This week, we review:
⭐Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
Efficient Differentially Private Fine-Tuning of LLMs via Reinforcement Learning
MaPPO: Maximum a Posteriori Preference Optimization with Prior Knowledge
Repositories (full list of curated repositories here):
⭐Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
I was at the ACL 2025 last week, where I saw many interesting presentations. This one by DeepSeek AI and co-authors got the best paper award.1 A good occasion to look back at what NSA is, even though we are far from exploiting its full potential. This paper was published in February on arXiv.
NSA (Natively Trainable Sparse Attention) is an attention architecture designed to handle long-context modeling more efficiently in LLMs. Long-context capabilities are increasingly important for applications like complex reasoning, multi-turn dialogue, and full-repository code generation. However, standard full attention mechanisms face serious performance and scalability issues as sequence length increases, with attention computation becoming the main bottleneck, accounting for up to 80% of latency in 64k-token sequences.
While various sparse attention techniques have been proposed to reduce this overhead by computing attention only over selected token pairs, most fail to translate their theoretical efficiency gains into real-world speedups. This shortfall is largely due to a lack of hardware-optimized implementations and inadequate support during training, which limits their usefulness in practical deployments.
NSA addresses these issues through a hierarchical token modeling framework that divides attention processing into three streams: compressed attention for broad patterns, selected attention for important token blocks, and sliding attention for local context. This design enables a significant reduction in per-query computation while maintaining the model’s ability to understand long-range dependencies.
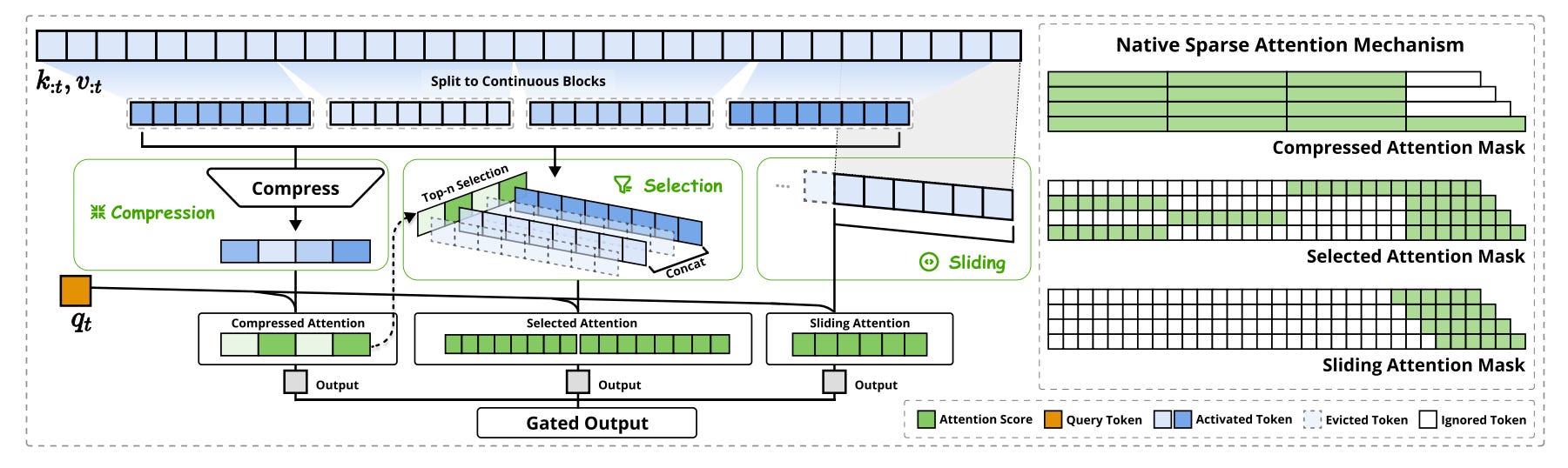
To ensure real-world usability, NSA incorporates custom GPU kernels optimized for memory access and Tensor Core utilization, enabling substantial speed improvements. It also supports end-to-end training with stable, trainable operators, which helps preserve model quality while reducing computational costs.
The architecture was evaluated on a 27-billion parameter transformer trained on 260 billion tokens. Results show that NSA matches or exceeds the performance of full attention baselines across language tasks, long-context understanding, and chain-of-thought reasoning, while delivering significant speedups during inference and training. These improvements become more pronounced with longer sequences, confirming NSA’s effectiveness in both performance and efficiency for long-context modeling.
Efficient Differentially Private Fine-Tuning of LLMs via Reinforcement Learning
This is not something that I see very often: A paper from Luxembourg! And a very good one.
LLMs power many applications, but their reliance on massive datasets, including sensitive, user-generated content, raises serious privacy concerns. Differential privacy (DP) has become a key requirement, but standard methods like DP-SGD often result in significant performance degradation due to rigid and globally applied clipping thresholds. These fixed parameters fail to adapt to varying training dynamics and gradient distributions, especially in deep models like transformers.
Several approaches have attempted to address this, including adaptive clipping techniques that adjust the clipping norm based on empirical gradient statistics. Others explore geometry-aware methods or federated learning settings to better balance utility and privacy. Still, most remain limited by coarse-grained parameter control and overlook long-term training dynamics.
The proposed framework, RLDP, reconceptualizes DP fine-tuning as a control problem. Instead of treating clipping and noise injection as fixed constraints, RLDP uses reinforcement learning, specifically, soft actor–critic (SAC), to dynamically adjust per-adapter clipping thresholds and global noise levels throughout training. It incorporates rich training statistics and operates within a strict privacy budget enforced by a DP accountant.
RLDP’s custom optimizer performs fine-grained pairwise clipping on LoRA tensors and supports heteroscedastic noise, enabling nuanced control. The policy is trained alongside the language model to maximize utility while minimizing privacy costs, effectively learning a curriculum that adjusts strategies over time based on the training phase.
Experiments across models like GPT-2, Llama-3, and Mistral-7B show that RLDP consistently outperforms prior methods. It achieves an average 5.6% improvement in utility (measured via perplexity) under the same privacy budget, and reduces training steps by 71% on average, cutting down both computational cost and environmental impact. All results are validated with Gaussian privacy accounting to ensure strict adherence to DP guarantees.
They released their code here:
GitHub: akhadangi/RLDP
MaPPO: Maximum a Posteriori Preference Optimization with Prior Knowledge
This paper addresses the limitations of aligning LLMs with human preferences using current methods like Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO). While RLHF has led to major improvements in model helpfulness and safety, it suffers from high computational costs, unstable optimization, and noisy feedback. DPO, a more efficient alternative, reframes preference learning as a maximum likelihood estimation (MLE) task over pairwise comparisons. However, DPO only considers relative differences between responses, ignoring absolute reward signals and leading to the “squeezing effect,” where both preferred and rejected outputs receive lower probabilities over time, degrading output quality and calibration.
To address this, the paper introduces Maximum-a-Posteriori Preference Optimization (MaPPO), a simple yet effective extension of DPO. MaPPO incorporates a log-prior term based on a calibrated reward gap, adjusting the learning signal based on how confidently one response is preferred over the other. This regularization mitigates the excessive penalization of near-tie responses and maintains stable, well-calibrated output distributions without adding complexity or computation overhead.
Experiments across multiple benchmarks (AlpacaEval 2.0, Arena-Hard, MT-Bench) and model families (Llama-3, Qwen2.5, Mistral) show that MaPPO consistently outperforms DPO and other advanced variants, improving alignment scores and win rates without altering the core optimization pipeline. The method supports both offline and online training settings and integrates with DPO variants like Iterative-DPO, SimPO, IPO, and CPO.
ACL 2025 was an excellent conference, but I have to say that the last half-day of the main conference was a very boring session overall. The ACL reserves now a half-day for award ceremonies, highlights (that was new), and self-congratulations. 50+ awards were given. Way too many. During the session, the speaker announced the awards, one by one, reading the paper titles. Such a waste of time for such a large conference (5k+ attendees). This could have been enough time to make another session of great research presentations.