
Sparse PEFT and Better LLM Meta-Evaluation
The Weekly Salt #3

In The Weekly Salt, I review and analyze in plain English interesting AI papers published last week.
Reviewed this week
⭐EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Scaling Sparse Fine-Tuning to Large Language Models
Can Large Language Models be Trusted for Evaluation? Scalable Meta-Evaluation of LLMs as Evaluators via Agent Debate
YODA: Teacher-Student Progressive Learning for Language Models
⭐: Papers that I particularly recommend reading.
New code repositories
I maintain a curated list of AI code repositories here:
⭐EAGLE: Speculative Sampling Requires Rethinking Feature Uncertainty
Speculative sampling relies on the selection of a draft model close to the original large language model (LLM), the one that we want to use for decoding, but with fewer parameters, to reduce latency without greatly sacrificing performance.
For example, in the Llama 2 series, the 7B model can serve as a draft for the 70B model, though finding a draft for the smallest 7B model poses challenges due to differences in instruction templates with alternatives.
While using a 7B model as a draft for larger models can provide some acceleration, its high operational overhead limits the efficiency of speculative sampling. Moreover, training a new draft model, smaller than 7B, specifically for this purpose is not cost-effective.
Efforts to improve speculative sampling focus on minimizing draft phase overhead and increasing the draft's acceptance rate by the original LLM. Techniques like Lookahead and Medusa have been developed to reduce latency in draft generation, yet they often yield drafts of lower accuracy.
EAGLE, a new framework proposed by this work, diverges from these methods by performing auto-regression at the feature level rather than predicting tokens directly, achieving higher draft accuracy and significantly enhancing acceleration and throughput for LLMs. EAGLE, which requires minimal training resources, can be easily integrated with other acceleration techniques to further reduce operational costs.
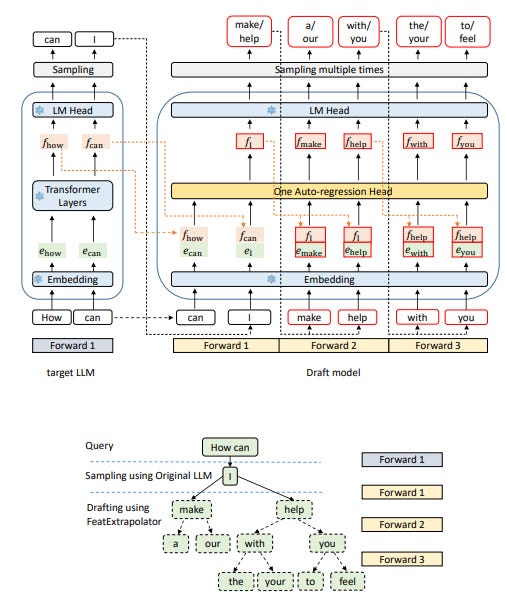
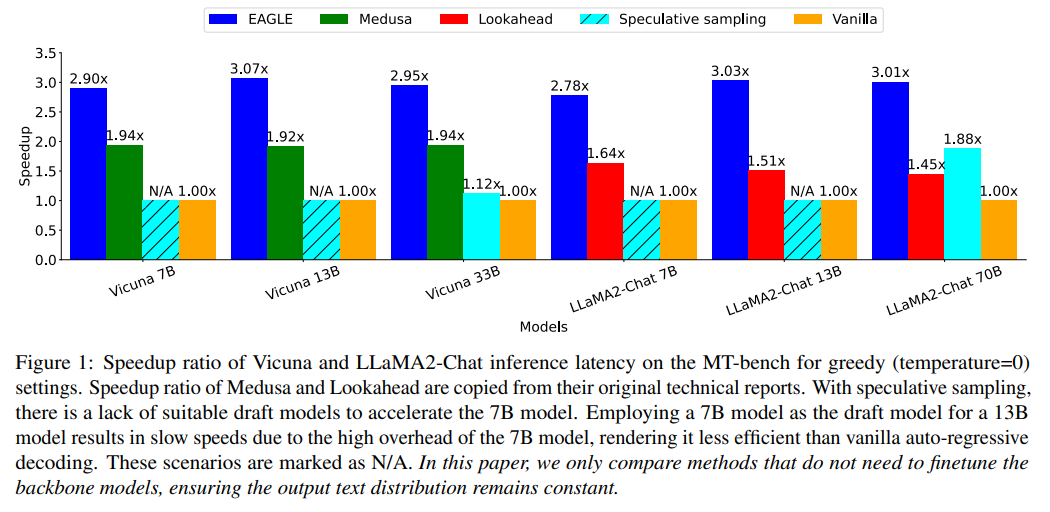
In the experiments conducted by the authors, EAGLE demonstrated up to three times the speed of conventional decoding methods and doubled the throughput.
They released their code here:
Note: EAGLE is not to be confused with Eagle 7B…
Scaling Sparse Fine-Tuning to Large Language Models
Recent progress in Parameter-Efficient Fine-Tuning (PEFT) methods has demonstrated significant potential by achieving a balance between maintaining a low parameter count and ensuring high model performance, without the need to add extra layers to LLMs.
This work particularly aims at updating LLMs sparsely in a memory-efficient manner to either match or exceed the performance of model full fine-tuning. By introducing an iterative approach to unstructured sparse fine-tuning, which includes updating, deleting, and adding indices based on specific criteria, this method seeks to scale memory usage linearly with the number of fine-tuning parameters instead of the total LLM parameters.
It works as follows:
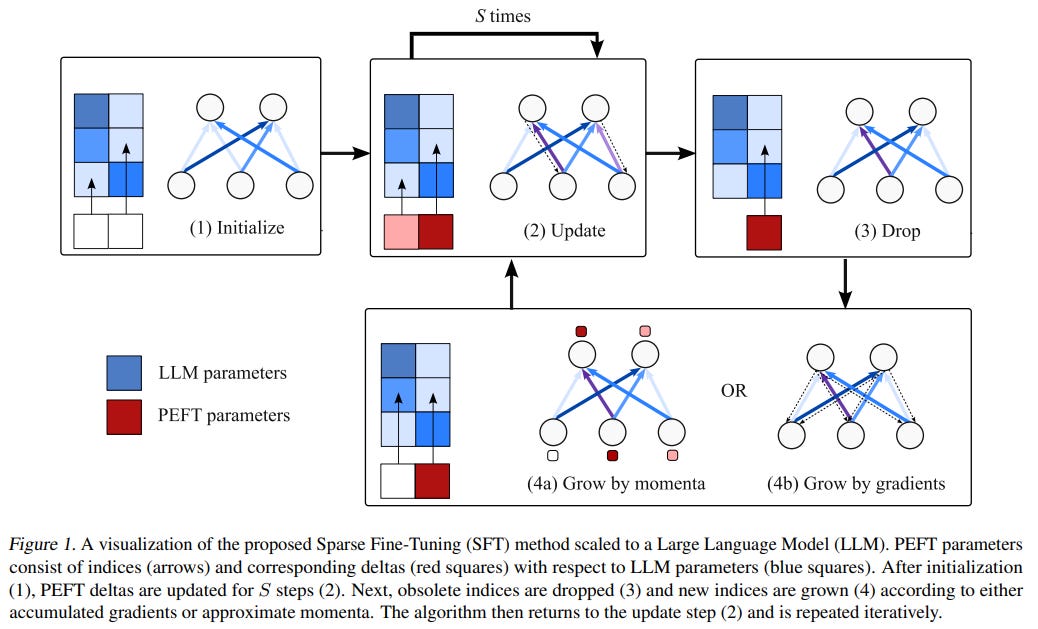
It also leverages efficient optimizers and approximates gradients to further enhance memory efficiency, particularly when gradients become less reliable.
Comparative evaluations of the proposed approaches against leading PEFT methods and full fine-tuning, using a variety of data sources and benchmarks, have shown that this approach consistently outperforms other methods in most tested scenarios, including under conditions of 4-bit LLM quantization.

They released their code here:
Meta-evaluation, which assesses evaluation metrics using human judgments, has been conducted in areas like machine translation and summarization with significant datasets such as WMT metrics and TAC/RealSum.
However, creating such datasets is expensive and complex, limiting their availability for new tasks as LLMs expand into various domains. This limitation often leads to the use of unverified LLMs as evaluators, raising concerns about their reliability.
This is becoming a prevalent issue as more and more scientific papers use LLMs, such as GPT-4, to evaluate their results without assessing whether they are reliable evaluators for a given task.
To better evaluate the evaluation abilities of LLMs, this paper presents SCALEEVAL, a meta-evaluation framework for LLMs. By leveraging debates among LLM agents with human oversight for disagreements, SCALEEVAL offers a flexible and efficient approach to evaluation. Testing by the authors demonstrates that SCALEEVAL aligns well with traditional human-based meta-evaluation. In other words, it might help to replace human evaluators with automated evaluations.
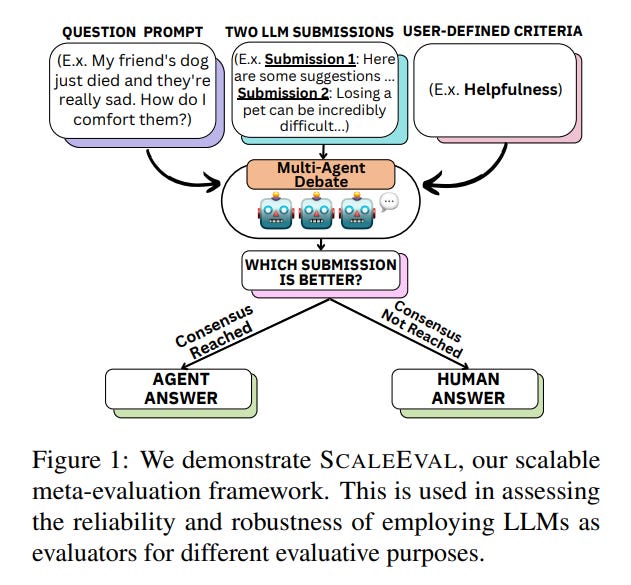
The framework is available as open-source and the authors encourage community participation in enhancing LLM evaluation methodologies:
This work is from the same lab that also reevaluated Google’s Gemini:

YODA: Teacher-Student Progressive Learning for Language Models
The development of LLMs mainly relies on static datasets, which might not cover all the necessary aspects for acquiring specific skills. In contrast, humans learn by effectively drawing lessons from a few examples. Human’s approach starts with basic problem-solving, moves to general problems, and finally tackles harder problems, all while incorporating continuous feedback from teachers to refine learning strategies. Our learning strategy, as humans, is very progressive. From this observation, we might want LLMs to adopt a more adaptive human-like learning method that allows for a broader and more systematic use of data.
Towards this direction, YODA introduces a new teacher-student progressive learning framework that mirrors the human learning process to enhance exploration and extrapolation from limited data, thereby improving the effectiveness of model learning.
YODA employs an interactive learning loop involving student and teacher agents. The student agent iteratively improves based on feedback from the teacher, who provides evaluative feedback and systematically organized questions. This process starts with basic problems and progressively introduces more complex challenges.
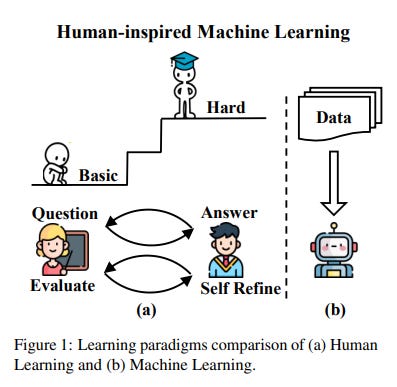
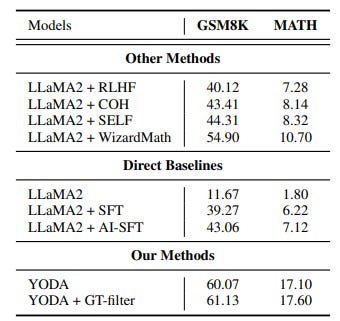
To validate YODA's effectiveness, this work applied it to a math reasoning task. They trained Llama 2 with YODA and the results show significant improvements over standard models, demonstrating that a curriculum-based learning approach and feedback-refinement cycle significantly bolster learning robustness and effectiveness.
This method could also be applied to other alignment methods, such as IPO and DPO.


If you have any questions about one of these papers, write them in the comments. I will answer them.